CNN Classification Using Novel Architecture on CIFAR 10 Dataset
I managed to acheieve 92.06% accuracy on the CIFAR-10 dataset, approaching state-of-the-art performance without using conventional transformers or attention mechanisms. Instead, this architecture implements adaptive pathway weighting through SoftMax normalization, allowing the network to dynamically focus on the most relevant features for each input.
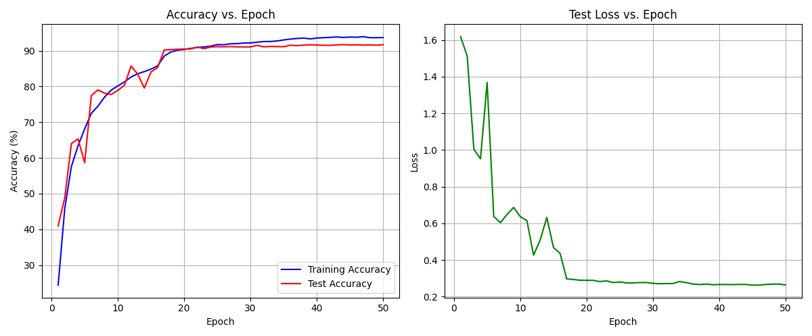
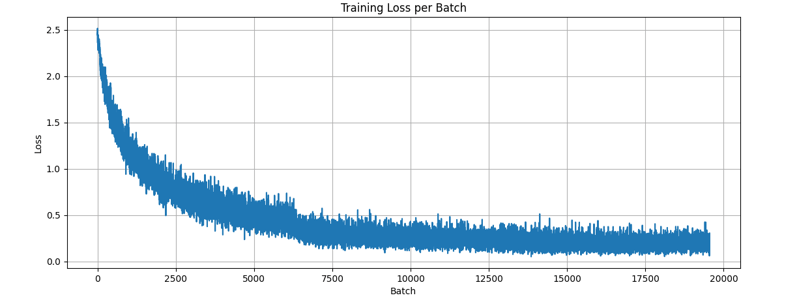
The minimal gap between training and test accuracy demonstrates good generalization with limited overfitting (figure 1), validating the effectiveness of the applied regularization techniques. And the smooth decrease in the training loss per batch(figure 2) shows effective training and optimisation parameters. The slightly more erratic test loss per epoch (figure 3) mirrors the red test curve in figure 1.
Figure 1
Figure 2
Figure 3
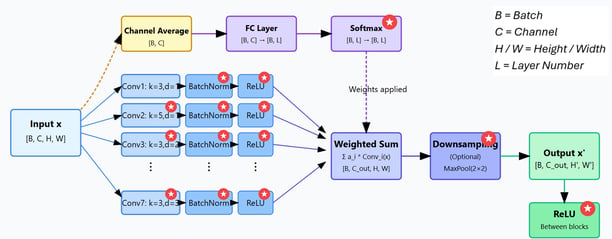
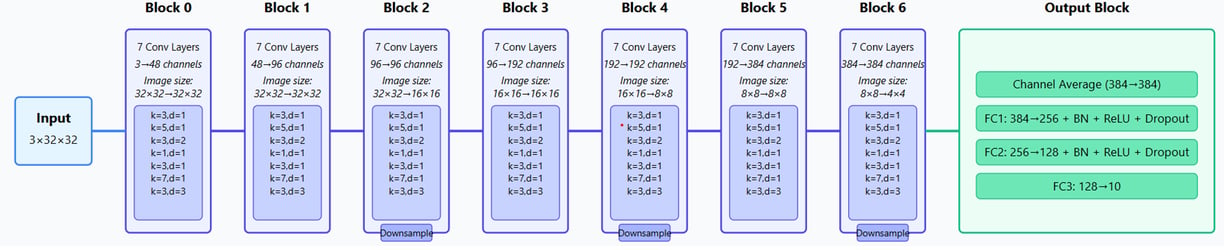
The overall architecture made use of the 7 unique layers repeating in each intermediate block. With 7 blocks used in total – the output of each becoming the input to either the next intermediate block or the output block. This design creates a progressively deeper feature hierarchy, with each successive block working with increasingly abstract representations of the original image.
Architecture
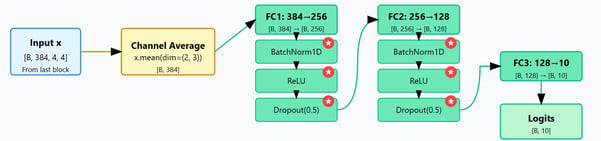
Output Block
Intermediate Block
The Intermediate Block is illustrated below. Each block receives an input image and processes it through 7 parallel convolutional layers with varying configurations. Each block dynamically computes weights for each convolutional pathway based on the input's channel averages, allowing the network to adaptively combine features.
The output block transforms the averaged channel features into classification logits through a sequence of 3 fully connected layers with progressively decreasing dimensions (256→128→10). This dimensional reduction pathway allows the network to gradually transform complex feature representations into class-specific information. Each layer except the final one incorporates BatchNorm and ReLU activation, enhancing training stability and feature expressiveness, while 50% dropout is applied to prevent overfitting by forcing the network to learn redundant representations. The final layer outputs the 10 logits corresponding to the CIFAR-10 classes without activation, providing raw scores for the cross-entropy loss function.